
.Net Architecture
This paper is a brief overview of the .Net architecture. That means it doesn't contain code you can use - rather, I try to show why so many people are excited about .Net.
You know that Microsoft started .Net to counter the threat that Java poses for them. Enterprise types will tell you that Microsoft needed a managed code environment to compete against Sun in the enterprise arena. More broadly, while Java has never really delivered on the "write once, run anywhere" idea, it has been pretty successful with "learn once, work anywhere." Java and Windows are the two biggest programming environments on the planet. The Java world may not be bigger than the Windows world, but it's been growing in a way that the mature Windows market hasn't. Microsoft can't afford to lose its base of programmers locked into Microsoft platforms, because that's what maintains the network effect that gives their OS franchise its value.
But there's a reason that Java has momentum, or did until relatively recently. Java is a nice environment, that seems to grow through both vendor fiat and Community process. The API is object oriented from bottom to top - no alphabetized lists of hundreds of flat function names in the Java world! - and Java's managed code environment means that some of the most common serious programming mistakes are simply not possible. This is a security feature, not just a Lazy Programmer Convenience - a system without buffer overruns is a safer system.
Microsoft can't beat Java with FUD. A straightforward Embrace And Extend won't work, either. They had to fall back on Plan C, which involved lots of hard work by lots of bright people.
Microsoft believes that Java's Achilles Heel is Java itself. That is, while the environment is great, you can't simply port legacy code to Java - you have to rewrite it. Now, maybe the dot com companies didn't have any code that was more than a year old, but that's not very typical. Many companies have decades worth of legacy systems. They can maybe be talked into porting their legacy code to a managed code system, but they definitely can't afford to rewrite all their legacy systems in a new language.
What .Net offers is all the advantages of Java, plus language neutrality. All .Net languages use the same object-oriented runtime library, and you'll have to learn that. But learning a new language is easy, it's learning the new library that's hard - once you know the new library, you can easily work in whatever language the legacy code du jour was written in.
So, both Java and .Net have the same two compelling features: an object oriented API and a managed code environment where you can never have loose pointers or memory leaks. Microsoft counters Java's "hippy culture" with the very corporate virtue of language neutrality.
It takes a lot of machinery to deliver these features. Try to keep them in mind as I do a bottom-up tour of the architecture, and you'll see them emerging from the details.
Common Abbreviated Names
| There are a lot of new names in the .Net world. I'll introduce them now, both to help orient you before getting into the details, and so that I can make cross-references without having to add distracting definitions of each new term as it comes up. |

|
The Common Language Runtime [CLR] is the managed code environment that everything else is built on. .Net is a garbage-collected environment but never interpreted - while .Net uses byte codes like Java, the Common Intermediate Language [CIL] code is always compiled, usually Just In Time [JIT] to be executed. (Yes, just like Java.) The Delphi compiler guys say that the jitter [the JIT compiler] compiles CIL about as fast as Delphi compiles Object Pascal, and that the object code that the jitter puts out is a lot like Delphi's object code. Only better, because the jitter can do function inlining.
The Common Type System [CTS] provides basic value types, type composition, type safety, objects, interfaces, and delegates. (Delegates are a multi-cast version of Delphi's events.) The Common Language Specification [CLS] is the subset of the Common Type System that all first class .Net languages need to share. Two .Net languages that have the same non-CLS type - like unsigned integers - can share values of that type, but there will be .Net languages which can't understand them. For example, Visual Basic doesn't have unsigned integers.
The .Net framework classes are the new run-time library, an object-oriented API roughly the same size as the Delphi BPL's. The framework consists of thousands of CLS-compliant C# classes that do just about everything from GUI programming to file IO to web services.
The runtime
That was the executive summary - more than your CEO will ever know about .Net. The rest of this paper provides more details.
Very broadly, the .Net core technology is composed of two big chunks of code: the runtime and the framework classes. The runtime is written in C++, while the framework classes are written in C#. .Net applications, and components that extend the .Net framework classes, can be written in whatever .Net language you prefer.
CLR
The CLR [once again, the Common Language Runtime] is the engine that drives every .Net application. It consists of the jitter [the Just In Time compiler] that compiles CIL [Common Intermediate Language] to native object code, the garbage collector, the Common Type System [CTS] and the exception handling machinery. The CLR gets threads and bulk memory management from the underlying operating system, and not much else.
The single most important thing you get from the CLR is managed code. With managed code, you can never dereference a "tombstoned" ("dangling") pointer, and so accidentally treat a TFont as a TStringList. Similarly, with managed code, you can never cast a TFont to a StringList - even a 'blind' cast like TStringList(ThisFont) will act like TFont as StringList.
Remember, managed code is not interpreted code - .Net maintains type safety and memory safety while running compiled object code.
Porting .Net to another platform starts with porting the CLR to the other platform. (Even if you can legally use Microsoft's framework CIL code, you'll have to port the WinForms library before desktop (GUI) programs will work.) It's not impossible that someone besides Microsoft - like Apple or even Ximian - could do a good job of this, as Microsoft has published the 2000 page core specification and had it approved as ECMA-335, but it is a very large, multi-year task. Still, when Borland R&D was asked about the possibility of Delphi on Macintosh OS/X at the US BorCon in May, they suggested that we're likelier to see Delphi for .Net running on .Net on OS/X than a native Delphi for OS/X. Similarly, they mentioned.Net on Linux as a possible future home for Kylix developers.
CIL
All .Net languages compile to CIL. (CIL was once known as Microsoft Intermediate Language, or MSIL.) .Net programs compile to something called an assembly, which is a standard PE [Portable Executable] exe or dll that contains a special header that says that the PE file contains CIL and .Net metadata instead of normal object code. Every entry point in the PE file is populated with stub code that causes the CIL to be compiled to actual object code on an as-needed basis. Metadata is a lot like Delphi's RTTI, but even more extensive.
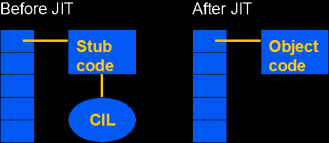
|
Before JIT
Each method is populated with stub code that compiles the CIL before running it.
After JIT
Each method is populated with actual object code.
|
Obviously, as-needed compilation does mean that the first call to a routine costs more than subsequent calls, but it's not a huge overhead both because CIL is so low-level and because the jitter doesn't have to handle parsing, linking, or macro expansion. Jitting also produces a couple of benefits. First, since the jitter only has to produce object code for a single machine, it can generate object code optimized for the machine it's running on. Second, there is a sense in which the jitter is a smart linker - code that is not used is not jitted and doesn't consume memory.
.Net applications can use the "reflection" API to emit CIL at runtime. This generated code will be jitted when called, just like any other CIL code. This lets spreadsheets and script languages compile expressions to CIL, which is in turn compiled on down to object code.
You may be interested in my expression compiler demo.
Industrial strength p-code
CIL is represented in a PE file by byte codes which are basically tokenized assembler that the jitter can quickly compile to actual native object code. The (free) .Net SDK includes the ILASM and ILDASM tools to compile symbolic CIL to a byte code PE file, and to disassemble a byte code PE file to symbolic CIL.
CIL is a verbose, strongly-typed assembler - yet CIL is also stack-based and generic. For example, CIL contains Push Integer and Push Float instructions, which will fail if the value to be pushed is of the wrong type, yet it also has only a single Add instruction, which operates on the two values on the top of the stack and can do type conversion as necessary. The strong typing built into CIL means that you simply can't make a boneheaded error like passing the wrong number of parameters to a procedure.
While CIL is low-level and easy to compile, it would be a mistake to think of it as a lowest common denominator programming language. There's no one language that uses all CIL features- CIL even has features, like support for tail recursion, that are only needed for languages that aren't even supported yet. CIL is also very easy to write: its use of a stack model means that you never have to worry about register allocation, and its RPN [Reverse Polish Notation] syntax makes it very easy to generate mechanically.
Memory and garbage collection
Most programmers have the same few objections when they hear about .Net. "What makes this any better than Java?"
"Oh, language neutrality. Yes, that makes sense."
"But, what about that JIT overhead?"
"No, I guess that doesn't sound that bad."
But then there's the Big One. It's usually not even phrased as a question: "Garbage collection sucks."
The only possible answer to that is No, it really doesn't suck. Garbage collection actually has a lot of nice features:
- Allocation is fast. The system is just advancing a pointer, not manipulating a linked list.
- Consecutive allocations are adjacent, not scattered all over the heap, which helps cache performance.
- Your code is smaller, simpler, and more reliable, because you never have to worry about who owns a block and because you never have to free the memory you allocate.
- You never have memory leaks. You never have data structures that refer to memory that's been freed.
These are four rather impressive advantages. Reference counting (like Delphi's strings, dynamic arrays, and interfaces use) offers the same no-need-to-free simplicity and safety, but you pay for it with the overhead of maintaining the reference counts - and reference counting can't handle circular references. (That is, if A refers to B, and B refers to A, neither reference count will ever go to 0.)
Garbage Collection Speed
You may be thinking that it doesn't matter how garbage collection can help you if it means your program might lock up for several seconds anytime it gets asked to do something. And you'd be right - that did suck, back in the '70's and '80's on Lisp machines and such.
But remember that this is Plan C. Microsoft did a lot of hard work, and their garbage collection doesn't suck. A full garbage collection - one that scavenges all freed memory and leaves all the free memory as a single contiguous chunk1 - takes less time than a page fault. Which you typically don't even notice.
Garbage collection can be so fast because memory life spans are distributed according to a power law. Most memory is freed quite soon after it's allocated. Most of what's left is freed within seconds or minutes. And most of what lasts longer than that lasts until the program shuts down.
So, the CLR has a three generation garbage collector. When the system has done 'enough' allocations (by default, this is tied to the size of the CPU's Level 2 cache), it does a generation 0 garbage collect. This looks at the most recently allocated blocks, and finds the ones that are still in use. The system only has to pay attention to the blocks that aren't garbage. These get moved down to the bottom of the partition, and promoted to generation 1, which means that the next generation 0 collection won't look at them. Once all the current data has been moved to the bottom of the partition, what's left is free memory.

When you've done 'enough' more allocation - or a generation 0 collection can't make enough room - the system does a generation 1 collection, which finds all the blocks that have become garbage since being promoted to generation 1. All survivors are moved and marked as generation 2, and won't be touched again until a generation 1 garbage collection can't make enough room. A generation 2 garbage collection just moves the surviving blocks down; it does not promote them to generation 3.
As you can see, this three generation garbage collection minimizes the time the system spends repeatedly noticing that a long-lived object is still alive. This in turn decimates the number of times a long-lived block gets moved. The idea of generations also saves time in a more subtle way. The way the system detects that an object is still live is to walk every reference from a set of "roots" on down. (It can do this because it has type data for every structure in the system. It knows every field of every structure.) This walk can stop as soon as it reaches an object that is a higher generation than the garbage collection: eg, every reference in a generation 1 object is to a generation 1 or 2 object, which a generation 0 sweep doesn't care about.
Finalization
Since the garbage collector can find all active references to any allocated object, the runtime doesn't need to track reference counts for strings, dynamic arrays, and interfaces. Not tracking reference counts can save a lot of time, especially with routines that pass their string parameters on to lower-level routines.
One thing that reference counting does do better than garbage collection is resource protection. That file will get closed, that visual cue will get restored, at the moment when your interface variable goes out of scope and the object is freed. With garbage collection, you can have a finalization routine that gets called when the block is scavenged, but you have no control over when it happens. This means that a whole class of "failsafe" Delphi techniques that rely on interface finalization are invalid under .Net.
Weak references
One final nice point about garbage collection is that it lets you have weak references, just like Java does. A weak reference is a reference to a bit of data that you can regenerate, if you have to, but that you'd like to keep around, if possible, because regeneration is expensive. This is useful for things like a browser cache, or relatively infrequently used singleton objects like the system Printer or Clipboard.When you need the data again, you can examine the weak reference's Target property, which will either contain a valid reference or Nil. If the Target is Nil, that means the memory has been garbage collected. If the Target is not Nil, you now have a normal (strong) reference, that will keep the data from being garbage collected just like any other normal reference does.
Exceptions
Delphi programmers are well aware of the virtues of exceptions. By removing the need to check that each operation succeeded, they allow complex chains of operations to be simpler and clearer. At the same time, since any failed operation can jump straight to an error handler, there's no risk that you will continue on as if your operation succeeded when it actually failed because some normally abundant resource was not available.
.Net supports exceptions at the CLR level, so you just can't hose Windows by trying to, say, draw on a DC that wasn't really created. You'll get an exception when you create the canvas, and so will never get to the code that actually used it.
Safe code
.Net does a lot to protect you from sloppy code. Managed code eliminates the risks from prematurely released memory and careless casts; exceptions remove the danger that code will assume a system state that it hasn't actually attained. .Net can also protect you from malicious code.
Because all assemblies speak the same (CIL) language and use the same (CTS) type system, Microsoft provides a utility - PEVerify - that can scan your code and prove that it doesn't do anything dumb that might lend itself to a cracker exploit. Code verification means you can be sure your enterprise code never uses uninitialized variables. Code verification means an ISP can run your ISAPI or ASP code with confidence.
CTS
The Common Type System [CTS] is a key component of the CLR's ability to prevent miscasting. All .Net languages understand each other's data types: They all use the same primitives, and information about composites (ie, records and objects) is part of the metadata in each assembly. A Visual Basic class can inherit from a C# class that inherits from a Delphi for .Net class, and (the equivalents of) is and as will work just as they should, in all three code-bases. (It's a lot like a cross-language version of packages.)
The CTS provides value types - scalars and records - and objects, and the ability to form composite types from the primitives. Objects are primitives, built into the lowest levels of the system; there's no sense in which they're something layered onto a flat API.
Objects
The .Net object model is a lot like the Delphi object model: all objects descend via single-inheritance from a single root object, System.Object, with support for properties, events, and interfaces. In fact, in Delphi for .Net, TObject will be an alias for System.Object - if it wasn't, then TComponent wouldn't be a System.Component, and Delphi components couldn't play in the common language space.
The problem with making TObject be a System.Object and with making TComponent be a System.Component is that there are plenty of places in the VCL class hierarchy where Delphi classes have methods and properties that their .Net counterparts do not. For example, System.Object doesn't have ClassName. Delphi for .Net will include a new "helper class for" syntax that will allow classes 'borrowed' from the .Net framework to have all the methods and properties that Delphi programs expect.
type
TServer = helper class(TBaseServer) for TClient;
The methods that a helper class adds to its client act just like they were declared in the client class. There's no special syntax to call them, and they're available to classes that descend from the client, just as if they were a normal part of the client class.
Interfaces
.Net supports interfaces, just like Java and Delphi do. There is, however, one key difference between .Net interfaces and Delphi's interfaces: Interfaces are not reference counted.
Obviously, .Net interfaces don't need to be reference counted, as all .Net data is 'freed' by the garbage collector. Equally obviously, eliminating reference counting lets the compiler generate faster and simpler code to deal with interfaces. No more maintaining reference counts on assignment; no more implicit finalization when an interface reference goes out of scope. For the most part, this is a change for the better. However, as I mentioned in the section on Finalization, this does break code that relies on interfaces for resource protection. (At least at the time I'm writing this) I think there's a chance that R&D can be persuaded to offer two types of interfaces - with and without reference counting - so that resource protection code can still work.
Even when garbage collections means that all objects have the freedom from the old Free What You Create rule that interfaces do in 'Classic' Delphi, interfaces will still offer three key features:
- Using interfaces increases your code's distance from implementation details. You only know that 'this' object can do 'that'; you don't know what type of object it is. You program to the interface, not the implementation.
- Paradoxically, interfaces also 'specificize' your code. Passing an object reference passes a reference to all its fields and all its methods. Passing an interface reference passes a reference to only the abilities you are actually using.
- Getting the problem semantics right is part of building a clear, reliable program. Components and interfaces are often a better model of the semantics of a problem than multiple inheritance. Inheritance is a strong, "is a" relationship, while supporting an interface is a weaker, "can do" relationship. In concrete terms, this means that you don't have big, heterogeneous objects, where this group of methods can inadvertently mess up the state that that group of methods depends on.
However, many programmers start using interfaces to take advantage of the fail-safe nature of reference-counted data: objects that you don't have to Free eliminate a whole large class of possible "failure points." It's only after they buy into the implementation advantages that they start to appreciate the design ideas embedded in the notion of interfaces. The disappearance of the reference-counting incentive may mean that interfaces are used even less in Delphi for .Net than in 'Classic' Delphi.
Dynamic aggregation
In Delphi, interfaces work well with components. An object like a form can claim to support an interface, and can delegate that interface to one of its object or interface properties via the implements keyword. Among other things, this lets an object change - at runtime - the way it implements an interface.
Since the CLR requires that all interfaces an objects supports be statically declared, it's not possible to support implements on .Net without a measure of compiler magic. As I understand it, Delphi for .Net may not support dynamic aggregation, at least in the first release - it's a low-priority research item.
Delegates, events, properties
.Net supports events and properties much like Delphi does. One key difference is that Delphi expects that an event is either handled or it is not. Each event can only have one handler, and if you want to do any sort of event multi-casting, you have to implement it yourself. Under .Net, every event is inherently multi-cast. Your code can add or subtract a particular "delegate" (the .Net term for a procedure of object), but it has no control over the order that delegates are called in, nor can it always find out what other delegates are handling the event.
A key design goal for Delphi for .Net is full support for all of .Net plus a very high degree of portability between Delphi for Windows and Delphi for .Net. Thus, Delphi for .Net will support both multi-cast event handlers and VCL-style singleton handlers. The set operators Include() and Exclude() will be extended to allow you to add and subtract event handlers from the multi-cast list, while you will still be able to set the OnEvent property to either Nil or a method with the right signature. Setting singleton event handlers won't affect multi-casting; Include() and Exclude() won't affect the singleton handlers. (Presumably the singleton handler will be implemented via a routine added to the multi-cast that does the traditional "if Assigned() then" code.)
Some old features will no longer be supported
R&D emphasizes that supporting .Net involves changes in Object Pascal syntax as big as those involved in adding units in Turbo Pascal 4, objects in 5.5, or classes and components in Delphi 1. Some old features are simply not .Net compatible:- GetMem, FreeMem, and ReallocMem. (Of course, dynamic arrays will still be supported, so you can use an "array of char" for IO buffers &c.)
- @ and Addr. There are no pointers in .Net, only references.
- Untyped var parameters.
- file of type. Record sizes depend on target architecture.
- BASM. (This appears to be more a matter of priorities than any principled opposition to inline CIL.)
Other features will disappear simply because they've been deprecated for a long time, and Borland doesn't want to carry them any farther forward:
- Absolute variables.
- The Real48 data type.
- ExitProc.
- Old style objects. However, records will be more like in C++ - they can have methods, and they can inherit from other records.
Finally, virtual constructors may not be possible under .Net. R&D knows that there is a lot of sophisticated code out there that relies on virtual constructors, but there are apparently obstacles to implementing virtual constructors that they may not be able to overcome. In the worst case, if virtual constructors do turn out to not be possible, you can always use RTTI to find the right constructor for any given class.
CLS
The Common Type System is 'bigger' than any one language; there is no language that takes advantage of all of its features. The Common Language Specification [CLS] is a subset of the CTS, the lingua franca that lets different languages interact. Because Visual Basic, C#, and Delphi for .Net all follow the Common Language Specification, a Visual Basic object can inherit from a Delphi object, and a C# object can in turn inherit from the Visual Basic object.
Some Delphi features - like sets and unsigned integers - are not CLS-compliant. This does not mean that you can no longer use them in your Delphi code, and it doesn't even mean that you can't export them as part of your cross-language component's public interface. What it does mean is that the compiler will warn you that you are using a non-CLS feature, and that you should include secondary features that manipulate your non-compliant features in a CLS-compliant way. For example, if you publish a set property, you should also publish methods that can Include() and Exclude() values and methods that can do tests like "This in That".
Happily for Delphi users, the CLS is case-insensitive, so that any libraries that 'natively' rely on case differences to separate one identifier from another will have to include case-insensitive aliases.
The CLS also requires that all languages use Unicode identifiers. Thus, programmers who don't think in English will be able to use identifiers that make sense to them. In a distinction that I don't quite understand, Delphi for .Net will allow 'characters' but not 'ideographs' - so you won't be able to use Chinese or Klingon characters in Pascal identifiers.
Framework
That's a lot to assimilate, but all that was just the runtime engine, the foundation. Unfortunately, there are thousands of classes2 in the C# "framework classes," so I can't even begin to introduce you to what is in the framework - the best I can do is give you an idea of why you should take the trouble to learn it.
The framework classes constitute the runtime library that all .Net languages and applications share. For portability between Delphi for Windows and Delphi for .Net you can just stick to the Delphi RTL wrappings for various framework features. However, to really take advantage of .Net, you should make an effort to learn the framework classes. Beyond what learning the framework classes can do for today's projects, learning the framework classes is what will make you a .Net programmer who can find work in any .Net shop on the planet. ["Learn once, work anywhere."]
You've probably all seen the dog and pony shows where .Net turns all the complexity of XML, SOAP, and WSDL into straightforward remote calls that pass objects between systems. This is great stuff - but there's a lot more to the framework classes than web services. .Net includes cryptography classes, Perl-compatible regex classes, and a great suite of collection classes that goes just light years beyond TList.
One thing to note is that even though C# is easy for Delphi programmers to read, you don't have to learn C# to learn the framework classes. Microsoft does not currently provide source to the library code, so that you can't Ctrl+Click on TObject.ToString and see the implementation, any more than you can Ctrl+Click on CreateCompatibleDC() in Delphi for Windows.
This is the future
Historically, the Windows API has been a set of 'flat' function calls. If you were feeling particularly charitable, you could say it was "object like", in that you created an object (like a window or a font) and then kept passing the "handle" to various routines that manipulated it. Of course, few people have ever been particularly willing to be quite so charitable. Learning the Windows API was always a slow and frustrating exercise, and almost all Windows code manipulates the flat API from behind various layers of incompatible object-oriented wrappers. Knowing MFC didn't help much with Delphi and vice versa.
More, if you weren't working in C or C++, you were always working at a disadvantage. When a new API came out, you'd either have to take the time to translate the headers and maybe write some wrapper classes yourself, or you'd have to wait for someone else to do it. Either way, there was always the danger that a translation might be wrong in some way - the pad bytes are off, an optional parameter might be required, a routine might be declared with the wrong calling convention, and so on.
All these problems disappear with .Net and the framework classes. The framework is object-oriented from top to bottom. No more "handles" to pass to an endless set of flat functions - you work with a window or a font by setting properties and calling methods. Just like Delphi, of course - but now this is the native API, not a wrapper. The wrapper classes are organized into hierarchical namespaces, which reduce the endless searching through alphabetical lists of function names. Looking for file functions? System.IO is a pretty logical place to look. Want a hash table like in Perl? System.Collections has a pretty nice one.
Finally, Microsoft promises that all future API's will be released as CLS-compliant parts of the framework class library. This means that your Delphi for .Net programs can use a new API the day it's released, without having to do any header translation, and without any danger that the header translation might be wrong.
You might be skeptical about that promise. Perhaps you remember that COM was once touted as Windows' object-oriented future. This is a sensible attitude - but .Net is a lot better than COM ever was. Most people's first COM experiments produced a sort of stunned disbelief at just how complex Microsoft had managed to make something as simple as object orientation. Most people's first .Net experiments leave them pleasantly surprised that something this good could have come from the same company that gave us COM and the Windows API.
.Net is Plan C. .Net is good, and .Net will be with us for a while.
| 1: | Well, there are actually different gcs for different size chunks, because generally lifespan scales with size - the larger the chunk the longer it lasts. [Back] |
| 2: | That sounds much more daunting than it really is. Many of those "thousands of classes" are internal, ancestor classes that you'll never touch directly. Many more are the results of operations on the 'primary classes' that you'll create directly - because garbage collection frees the framework classes from the Free What You Create rule of unmanaged code, functions that return new objects are very common in the Framework Class Library. [Back] |